DualPath Inference Mechanics: The Hidden Infrastructure Challenge Behind Agentic AI
The Quiet Inversion Nobody Is Talking About
For the last several years, the conversation around Large Language Model (LLM) inference has been dominated by a single assumption: GPU compute is the primary bottleneck. Organizations have invested heavily in larger accelerators, faster tensor cores, optimized attention kernels, and increasingly sophisticated Mixture-of-Experts (MoE) architectures to improve performance.
However, a recent research paper titled *DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference* challenges this assumption for a rapidly growing class of workloads: long-running, tool-using, multi-turn AI agents.
The authors argue that modern agentic workloads are no longer compute-bound. Instead, they are increasingly constrained by storage bandwidth and data movement. In other words, the challenge is no longer generating tokens quickly—it is moving context efficiently.
This shift has important implications for organizations building enterprise-grade AI systems.
Why Agentic Workloads Change Everything
Traditional chatbot interactions are relatively simple. A user submits a prompt, the model generates a response, and the conversation typically ends after a few turns.
Agentic systems operate very differently.
These systems may:
- Execute hundreds of reasoning steps
- Interact with external tools and APIs
- Maintain long-term context
- Perform iterative planning and execution
According to the DualPath research, production coding-agent workloads exhibit:
- Mean trajectory length of 157 turns
- Average context lengths of approximately 32,700 tokens
- Average append size of only 429 tokens per turn
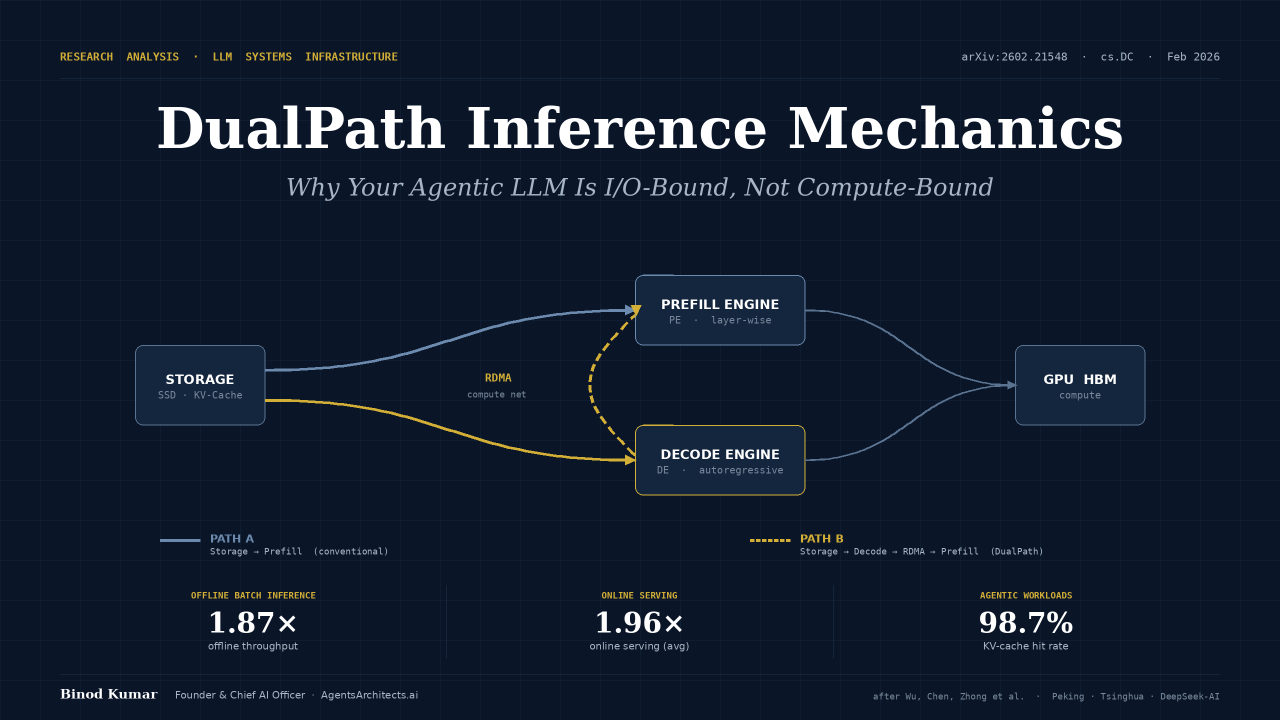
- KV-cache hit rates approaching 98.7%
These numbers fundamentally change the economics of inference.
When nearly all previously processed context is reused, the model spends far more time loading KV-cache data than performing fresh computation. The workload becomes dominated by data movement rather than matrix multiplication.
Understanding the Cache-Compute Imbalance
To quantify the challenge, the researchers introduce a metric known as the cache-compute ratio, measured in gigabytes per petaflop (GB/PFLOP).
Even highly optimized frontier models require substantial KV-cache movement relative to available compute resources.
The paper demonstrates that modern GPUs have become dramatically faster while the infrastructure responsible for supplying data has not improved at the same pace.
As a result, GPUs frequently sit idle waiting for cached state to arrive.
This represents a major architectural shift.
The bottleneck is no longer the accelerator itself—it is the pathway used to feed data into the accelerator.
The Rise of Prefill-Decode Disaggregation
Most modern large-scale inference systems rely on a serving architecture known as Prefill-Decode (PD) Disaggregation.
In this architecture:
Prefill Engines (PEs)
Responsible for processing large context windows and creating the initial KV-cache.
Decode Engines (DEs)
Responsible for token generation and latency-sensitive decoding.
This separation improves efficiency and has become the standard deployment model for large-scale AI serving systems.
However, DualPath identifies a hidden inefficiency within this design.
While Prefill Engines continuously load KV-cache data from storage, Decode Engines often have unused storage-network capacity.
One side of the system becomes saturated while the other remains underutilized.
The result is a classic resource imbalance problem.
The Core Insight Behind DualPath
The key innovation of DualPath is surprisingly simple.
Instead of forcing all KV-cache reads through the Prefill Engine, the system allows both Prefill Engines and Decode Engines to participate in cache loading.
This creates two independent pathways:
Path A: Traditional Prefill Path
Storage → Prefill Engine → GPU Memory
Path B: DualPath Route
Storage → Decode Engine → Compute Network → Prefill Engine → GPU Memory
A centralized scheduler dynamically determines which path should be used for each request.
By leveraging previously unused network capacity on Decode Engines, the system balances traffic across the cluster and reduces storage bottlenecks.
Rather than adding more hardware, DualPath improves utilization of infrastructure that already exists.
Solving the Engineering Challenges
Implementing DualPath in production environments introduces several technical challenges.
1. Traffic Isolation
Inference traffic is highly latency-sensitive.
DualPath uses network-level Quality of Service controls to ensure that KV-cache transfers do not interfere with critical inference operations.
2. Efficient Fine-Grained Transfers
KV-cache data is often fragmented into many small pieces.
The researchers optimize data movement using RDMA-based transfers and batching techniques that significantly reduce transfer overhead.
3. Adaptive Scheduling
The system continuously balances:
- Network utilization
- Storage utilization
- GPU workload distribution
This dynamic scheduling ensures that resources remain efficiently utilized under changing workloads.
Performance Results
The reported results are significant.
Across real-world agentic workloads, DualPath achieves:
- Up to **1.87× throughput improvement** for offline batch inference
- Approximately **1.96× throughput improvement** for online serving workloads
- Improved resource utilization without violating latency objectives
These gains are achieved without requiring additional hardware investments or modifications to the underlying model architecture.
Why This Matters for Enterprise AI
For organizations deploying AI agents in production, the implications are substantial.
The cost profile of agentic systems differs dramatically from traditional chatbots.
A chatbot's cost is primarily driven by generated tokens.
An AI agent's cost is increasingly driven by:
- Context retention
- KV-cache management
- Storage bandwidth
- Network efficiency
As agent workflows become longer and more sophisticated, infrastructure design becomes just as important as model selection.
Key Takeaways for AI Builders
Audit Your KV-Cache Strategy
Many organizations focus on model optimization while overlooking cache architecture.
Efficient KV-cache management may deliver larger gains than model-level improvements.
Monitor Emerging Inference Infrastructure
Technologies such as:
- DualPath
- 3FS
- DeepEP
- FlashMLA
are rapidly becoming foundational components of modern AI infrastructure.
Expect the Bottleneck to Move
Today's bottleneck may be storage bandwidth.
Tomorrow it may be:
- DRAM bandwidth
- RDMA scaling
- Scheduler efficiency
- Memory hierarchy limitations
Successful AI platforms will be designed to adapt as infrastructure constraints evolve.
Final Thoughts
The most important lesson from DualPath is not that storage bandwidth is permanently the dominant bottleneck.
The real lesson is that bottlenecks evolve alongside workloads.
As AI systems transition from short conversations to long-running, tool-using agents, the infrastructure stack must evolve as well.
The era of treating inference as a black box is ending.
Organizations building the next generation of enterprise AI systems will increasingly need to understand not only how models think, but also how data moves through the infrastructure that powers them.
References:
- Wu, Y., Chen, S., Zhong, Y., Huang, R., Tan, Y., Zhang, W., Zhang, L., Zhou, S., Liu, Y., Zhou, S., Zhang, M., Jin, X., & Huang, P. (2026).
- DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference*. Peking University, Tsinghua University, and DeepSeek-AI.
Available at:
https://arxiv.org/abs/2602.21548
Author Note
This article is a technical interpretation of the DualPath research paper and related LLM inference systems literature. All benchmark figures, throughput improvements, architectural descriptions, and empirical observations are derived from the cited works. Analysis, interpretation, and practitioner implications reflect the author's perspective.